前言
Huginn是一个神器,见到它有一种相见恨晚的感觉,我们都知道IFTTT是一个信息的触发器,可以用来建立自动的工作流。而Huginn是IFTTT的加强版,几乎可以将所有的信息进行重组、变形、输出,真正做信息的主人。
因为最初找到Huginn的时候是寻找一款能够将不支持feed的网站生成feed的方式,因此本文着重从这个角度介绍。

方案选择
Huginn的安装有多种方式:
- Docker的方式安装在本地
- 安装在Linux Server
- 安装在Heroku
Docker的方式是最无痛的,Docker相当于是一个沙盒环境,在沙盒中配置好服务,开放个端口给外部,就可以调用服务了。不过Docker方式安装在本地,生成的rss文件也是一个本地路径,并不能放到RSS阅读器中。因此这种方式适合先熟悉下Huginn的配置。具体的安装方法可以Google搜“Huginn Docker安装”获得。
安装在Linux Server的方式最理想,不过技术复杂度也最高,官方有很完善的安装说明:Installation from source,不过尝试的过程中困难重重,遇到了很多问题。其中最重要的一个问题是VPS内存不足,本身VPS内存512M,Huginn要求至少有0.5G的内存和0.5G的swap空间,好不容易安装上去运行起来也经常报错。
安装在Heroku的方法最推荐,熟练的话十几分钟就能配置完毕。Heroku是一个支持Ruby的云平台,因为Huginn本身是基于Ruby的,因此使用Heroku来部署会省去很多环境准备的步骤。
搭建Huginn环境
准备工作
- 注册Heroku平台账号
- 准备编译环境,如果本地机器是一台Mac/Linux的话,可以使用该环境;如果本地是Windows的话,可以安装Linux虚拟机。不过更推荐的方式是使用云端环境,例如Could9,免费的方案足够了,下面以Cloud9来说明。
- 进入C9,创建一个新的private空间,template选择ruby。

- 一段时间的配置后会看到控制界面,右下方的bash中可以输入命令,然后安装Heroku Toolbelt
安装Huginn
- 登录Heroku:
heroku login,输入账号密码 - 创建huginn app:
heroku create huginn-sample(可以自己命名) - Clone app到C9:
heroku git:clone --app huginn-sample - Clone Huginn的主程序到C9:
git clone https://github.com/cantino/huginn.git - 将Clone来的Huginn文件夹内的内容复制到huginn-sample文件夹中,注意隐藏文件也需要复制。复制隐藏文件小窍门:
cp dir1/. dir2 -rf - cd到huginn-sample文件夹内:
cd huginn-myifttt,随后输入cp .env.example .env,完成后再输入bundle,这一步会花费比较长的时间. - 提交代码变更:
git add .、git commit -am 'commit code'; - 最后,执行脚本:
bin/setup_heroku,运行过程中会有几处提示,请按照提示输入,这一步运行时间也比较长,请耐心等待。 - 部署完成,尽情享用吧!更多安装细节请参考:部署到 Heroku
小技巧:Heroku设置时区使Huginn任务运行更准时:
heroku config:add TZ="Asia/Shanghai"
使用Huginn生成输出全文的RSS
Huginn最大的能力是对信息的重组,从繁多冗杂的信息中提取出需要的信息。对于网站来说,我们把它看做信息源,那么这个信息源何时更新、更新了什么、是不是我们关系的内容,就是一个很重要的信息。Huginn能够替我们做的就是将需要的信息提取出来,组织成RSS Feed的形式,定时推送给我们。
这个过程有三个主要步骤,在Huginn中是通过agent来完成的,可以将agent理解为一个个车间,每个车间有它自己的作用,那么我们需要的三个车间是:
- 下载原始信息,将url、标题等信息抓取下来
- 根据url下载相应页面的全文(关于RSS全文输出的优势可以看这篇博客)
- 输出成规范的RSS格式
下面分两种情况进行说明。
网站内容生成RSS
解析原始页面
创建一个Website Agent,取一个名字,schedule代表该agent运行的频率,其他可以暂时不改,Options里面是主要的操作。
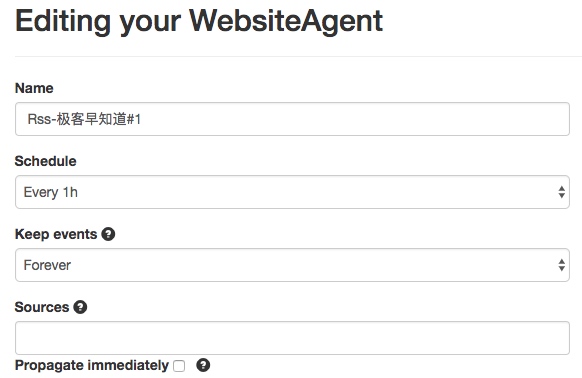

- url填入需要解析的页面
- type表示格式,可以有html, xml, json, text多种格式
- mode表示信息的输出处理方式,“on_change”表示仅输出下面的内容,”merge”表示新内容和输入的agent内容合并。
- extract是我们要提取的信息,这里需要xpath和css知识。一个简单地确定xpath路径的方式是使用chrome的Inspect功能,如下图。
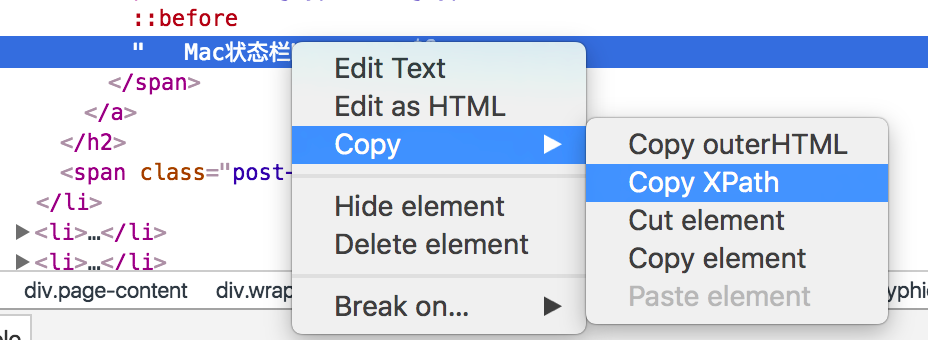
- 依次将标题、摘要、URL都抓取下来
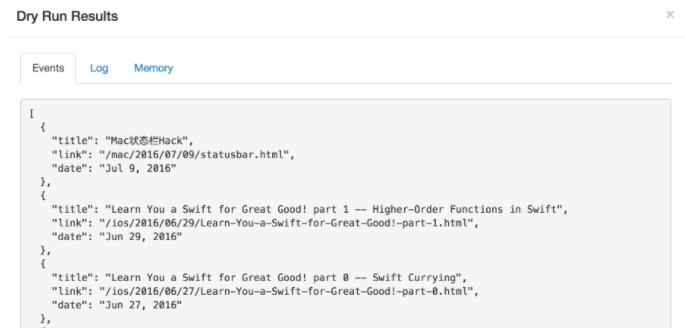
- 使用Dry Run看下效果,保存
小技巧:某些时候页面有防爬虫检测功能,这时候需要设置UA:
user_agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36
全文输出
这步的主要步骤是使用前一步生成的url抓取原始页面中的全文内容。新建一个Agent,在source中填入上一步的agent,意即使用上一个agent生成的events作为输入。

与上一个Agent不同的地方在于:mode选择“merge”,value填入“.”,即原样输出全文并合并原先的输出。

生成RSS
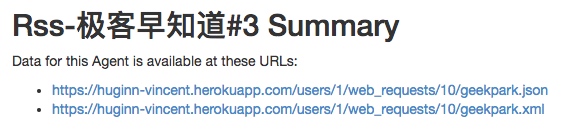
生成RSS的Agent叫Data Output Agent,Sources中填入第二步的Agent名称,配置如下:

save后,可以在Summary中看到RSS链接。
微信公众号内容生成RSS
微信公众号内容获取有一些不一样的地方,本身公众号并没有一个列表页供抓取。原先可以利用Sogou的微信搜索来间接实现,不过不知从何时起,搜狗中的账号列表页变成了js动态生成,目前可行的办法是通过第三方的聚合平台来实现,如:传送门,其他操作和上述网站操作方式一致。
使用FeedBurner发布Feed
FeedBurner是Google提供的一项服务,用于将任意feed地址转换成一个可全网发布的地址,这个服务有两方面的好处:
- 生成的Feed地址可能会发生变动,burn之后能保证最终生成的地址固定
- burn后的地址方便统计和推送
FeedBurner的地址:https://feedburner.google.com, 使用非常简单,基本就是填入地址一路next就行:

最终生成的Feed地址如:http://feeds.feedburner.com/herokuapp/ckBV
使用Inoreader阅读生成的地址
自从Google Reader死了之后,第三方的Rss阅读工具越来越少,Inoreader算是体验做得很不错的,将上面生成的地址填入订阅后就可以开始阅读啦。
根据自己的需求,添加更多的Feed,同时结合一些本身已经对外提供Rss的网站,就构建出了自己的私人信息中心,从此把自己从垃圾信息的海洋里解放出来吧!
至于如何构建一个合理的信息中心以及有哪些优质源推荐,后面会写个专题详细说。
更多Huginn的用法
其实Huginn还有很多高级用法,比如:
- 监控天气预报,如果明天下雨,则给你发送提醒;
- 监控某款商品的网页,一旦降价,通知你;
- 监控游戏官网,一旦游戏有发售或新动态,通知你;
- ……
官方网站上有很多应用实例,有时间来一一研究下。
参考资料
- 安装在Linux server的官方指南:Installation from source
- Heroku部署说明:部署到 Heroku
- Huginn安装教程—建立你自己的IFTTT
- Huginn中文指南:搭建自己的iFTTT
- 让所有网页变成RSS —— Huginn